运算符(operator)、表达式(expression)和语句(statement)是组成 C 程序的三个最基本的语法结构。在 C 语言中,这三种概念之间一般呈“包含”关系,即表达式中通常含有运算符,而语句中也可以包含有表达式。最终,众多的语句便组成了一个完整的 C 程序。
C 运算符的分类
在目前最新的 C17 标准中,C 语言一共有 48 个运算符。按照这些运算符功能的不同,我们可以将它们分为七类(分类方式并不唯一),如下表所示:
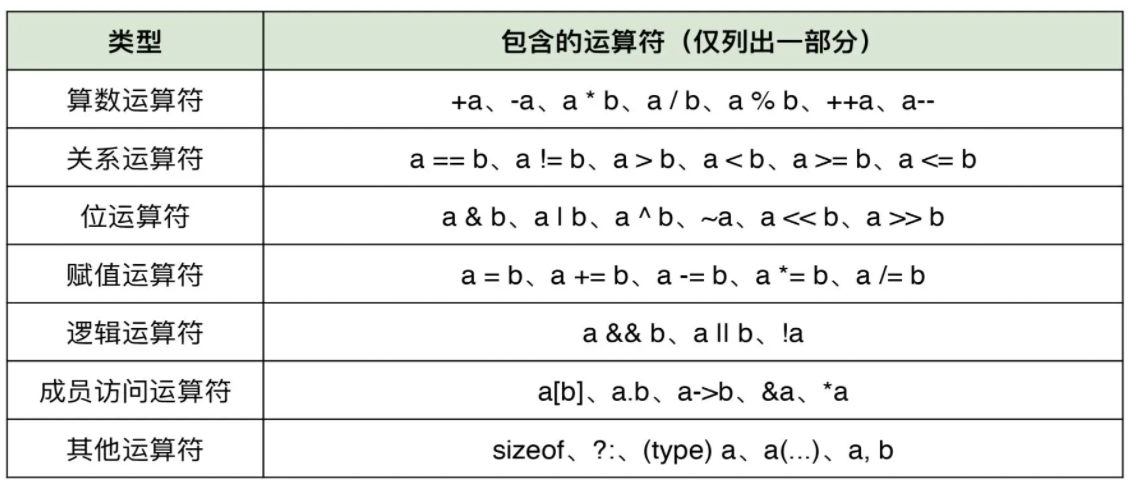
这七类运算符在功能上均有所不同,因此,使用机器指令进行表达的具体方式和复杂程度也不同。其中,算数、关系、位与赋值运算符由于功能较为基础,可以与某些机器指令一一对应。而逻辑运算符、成员访问运算符及其他运算符,实现相对复杂。
算数、关系、位、赋值运算符等算术运算符
算数、关系、位、赋值这四类运算符在经过编译器处理后,一般都可以直接对应到由目标平台上相应机器指令组成的简单计算逻辑。
FLAGS 寄存器
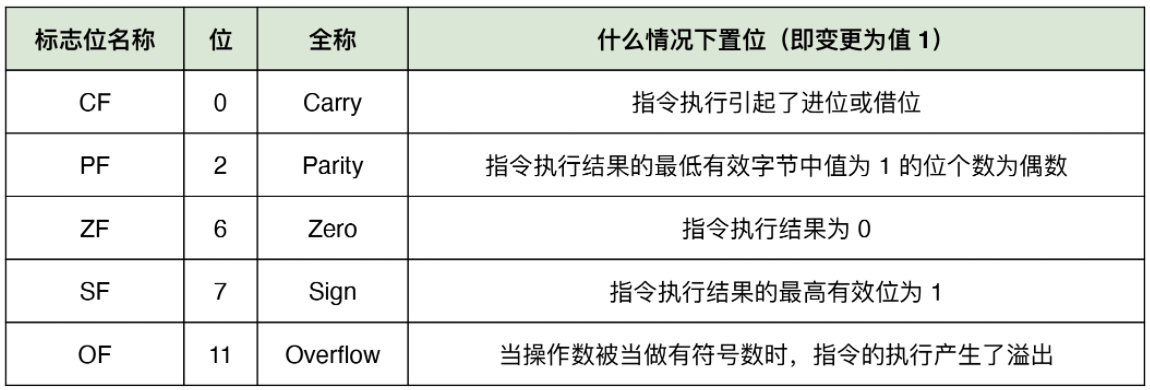
FLAGS 寄存器是一组用于反映程序当前运行状态的标志寄存器。许多机器指令在执行完毕时,都会同时调整 FLAGS 寄存器中对应位的值,以响应程序状态的变化。setg 便会通过查看 FLAGS 寄存器中的 ZF 位是否为 0,且 SF 与 OF 位的值是否相等,来决定将寄存器 al 中的值置 1,还是置 0。因此,FLAGS 寄存器的状态满足指令 setg 的置位条件(ZF=0 且 SF=OF),al 寄存器的值将被置 1。
逻辑运算符
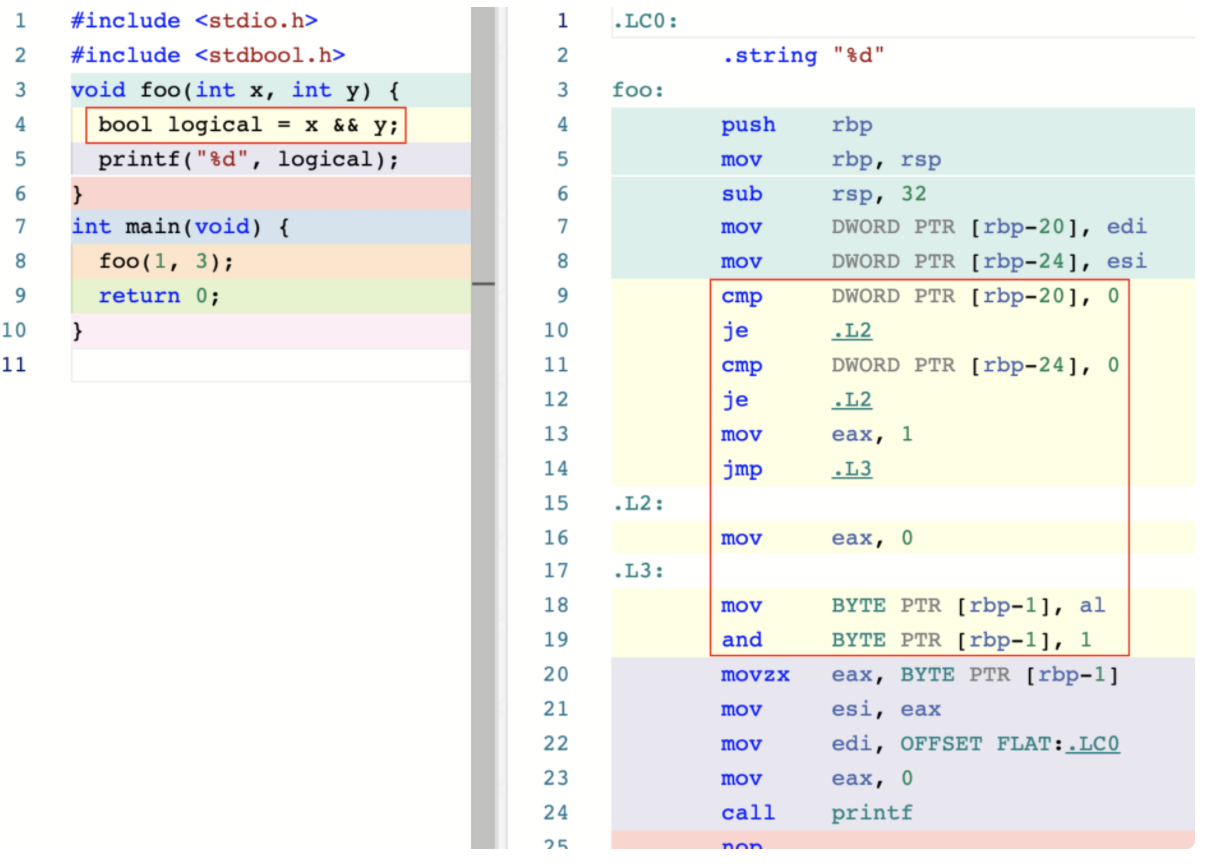
说完这四种较为直观的运算符,让我们再来看看逻辑运算符。这里,我们直接以逻辑与运算符 “&&” 为例,来看看编译器是如何实现它的。该类别下的其他运算符,实现方式与其类似,区别仅在于使用的具体指令可能有所不同。首先,我们还是来看一段示例代码:
在 C 标准中,逻辑与运算符 “&&” 的语义是:如果它左右两侧的操作数都具有非零值,则产生计算结果值 1。而如果任一操作数为 0,则计算结果为 0。不仅如此,标准还规定了该运算符在执行模型中的求值规则:如果通过逻辑与运算符左侧第一个操作数的求值结果就能确定表达式的值,就不再需要对第二个操作数进行求值了,这也就是我们常说的“短路与”。
逻辑与运算符并没有可与之直接对应的汇编指令。并且,为了满足“短路”要求,编译器在非优化的实现中通常会使用条件跳转指令,比如 je。je 指令会判断当前 FLAGS 寄存器中的标志位 ZF 是否为 0。若为 0,则会将程序执行直接跳转到给定标签所在地址上的指令。
上图中右侧输出的汇编代码里,程序会按顺序将位于栈内存中的变量 x 和 y 的值与数值 0 进行比较。若其中的某个比较结果相等,程序执行将会直接跳转到标签 “.L2” 的所在位置。在这里,值 0 会被直接放入寄存器 eax。而若变量 x 与 y 的值判断均不成立,则值 1 会被放入该寄存器。紧接着,标签 “.L3” 中的指令将接着执行。到这里,寄存器 eax 中的值将会被作为最终结果,赋值给变量 logical。
在非优化版本的实现中,编译器使用了 je 条件跳转指令。其实,现代流水线 CPU 通常会采用一种名为“投机执行”的方式来优化条件跳转指令的执行。所谓投机执行,是指 CPU 会通过分析历史的分支执行情况,来推测条件跳转指令将会执行的分支,并提前处理所预测分支上的指令。而等到 CPU 发现之前所预测的分支是错误的时候,它将不得不丢弃这个分支上指令的所有中间处理结果,并将执行流程转移到正确的分支上。很明显,这样就会浪费较多的时钟周期。
就逻辑与运算符来说,在使用高编译优化等级时,编译器还可能会采用下面这种方式来实现该运算符。这里,我们看到了新的汇编指令: test 、setne 和 movzx 。
test edi, edi ; edi <- x.
setne al
test esi, esi ; esi <- y.
setne sil
movzx esi, sil
and esi, eaxtest 指令的执行方式与 cmp 类似,只不过它会对传入的两个操作数做隐式的“与”操作,而非减法操作。在操作完成后,根据计算结果,指令会相应地修改 FLAGS 寄存器上的 SF、ZF 以及 PF 标志位。另外的 setne 指令则与 setg 指令类似,该指令将在 ZF 为 0 时把传入的寄存器置位,否则将其复位。最后的指令 movzx 实际上是 mov 指令的一种变体。这个指令将数据从源位置移动到目标位置后,会同时对目标位置上的数据进行零扩展(Zero Extension)。
编译器在高优化等级下对逻辑与运算符的实现方式:首先,通过 test 指令,程序可以判断参数 x 与 y 是否为非零值。若为非零值,则相应的寄存器会被指令 setne 置位。在这种情况下,寄存器 al 与 sil 中便存放有用于表示变量 x 与 y 是否为零的布尔数字值 0 或 1。接下来,通过数据移动指令,寄存器 sil 中的值被移动到寄存器 esi 中。最后的 and 指令又会对 x 与 y 的布尔数字值再次进行与操作,得到的最终结果将被存放在目的寄存器,即 esi 中。这种实现方式大量减少了对栈内存以及条件跳转指令的使用,使得程序减少了访问内存时产生的延迟,以及由于分支预测失败而导致的 CPU 周期浪费,从而执行性能得到了提升。
成员访问运算符
看看成员访问运算符。这里我以取地址运算符 “&”、解引用运算符 “*” 为例,来介绍编译器对它们的实现细节。来看下面这段代码:
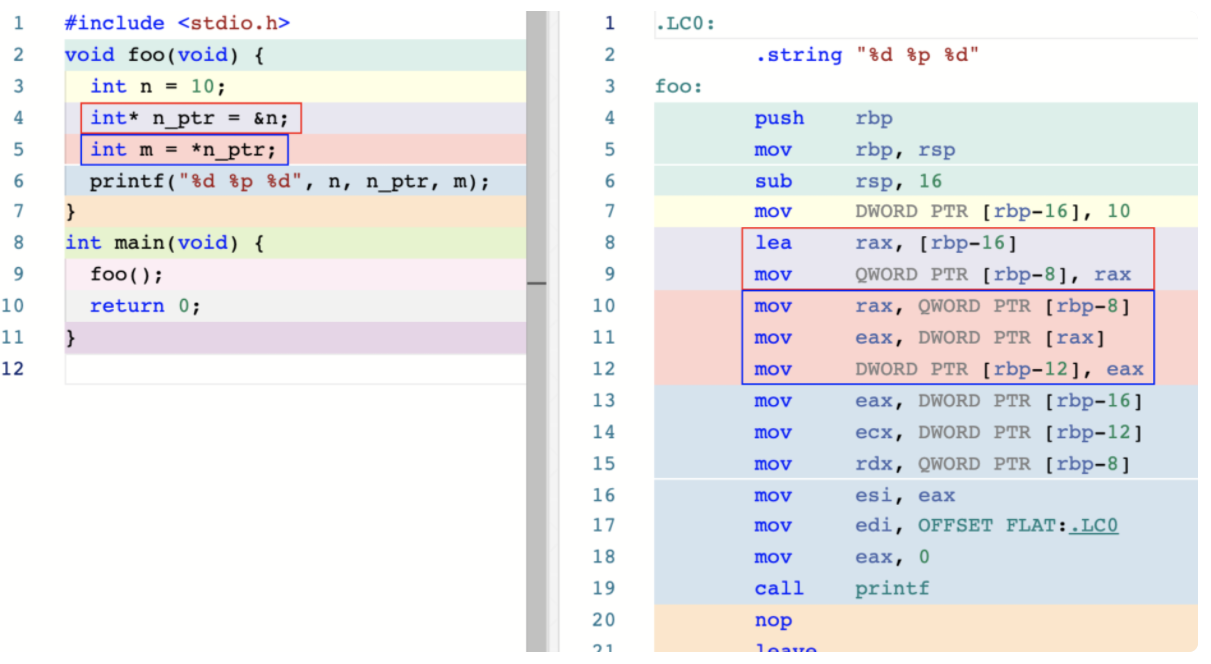
如上图中红色框对应的 C 代码和汇编代码所示,对于取地址运算符 “&”,实际上它一般会直接对应到名为 lea 的汇编指令。这个指令的全称为 “Load Effective Address”,顾名思义,它主要用来将操作数作为地址,并将这个地址以值的形式传送到其他位置。比如,上面代码中的 lea 指令将寄存器 rbp 中的值减去 16 后,直接存放到寄存器 rax 中,而此时该寄存器中的值就是局部变量 n 在栈上的地址。
而解引用运算符 “*”的行为与取地址运算符完全相反。当需要对位于某个地址上的值进行传送时,我们可以直接使用 mov 指令。上图中,在蓝色框的汇编代码里,第一条 mov 指令将变量 n_ptr 的值传送到了寄存器 rax 中。随后,第二条 mov 指令将 rax 寄存器中的值作为地址,并将该地址上的值以 DWORD,即 32 位值(对应 int 类型)的形式传送到 eax 寄存器中。最后,第三条 mov 指令将此时 eax 寄存器中的结果值传送到了变量 m 在栈内存上的存储位置。
至于该类别下的其他运算符,因为它们的本质都是访问位于某个内存地址上的数据,因此实现方式大同小异。
其他运算符
最后,让我们来看看除了上面那六类运算符之外的其他运算符,这里我主要介绍 sizeof 运算符和强制类型转换运算符 “**(type) a**”。

其中,sizeof 运算符是一个编译期运算符,这意味着编译器仅通过静态分析就能够将给定参数的大小计算出来。因此,在最终生成的汇编代码中,我们不会看到 sizeof 运算符对应于任何汇编指令。相反,运算符在编译过程中得到的计算结果值,将会以字面量值的形式直接“嵌入”到汇编代码中使用。你可以从上图中右侧红框内的汇编代码看到,C 代码 sizeof(int) 的计算结果 4 直接作为了 mov 指令的一个操作数。
至于强制类型转换运算符呢,其实也很好理解。这里,我们将变量 n 的值类型由原来的 size_t 转换为了 short。你可以从上图中蓝框内的汇编代码里看到,当 mov 指令将变量 n 的值移动到变量 f 所在的内存区域时,它仅移动了这个值从低位开始一个 WORD,即 16 位大小的部分。至于其他类型之间的转换过程,你可以简单理解成对同一块数据在不同机器指令下的不同“解读”方式。
在高编译优化等级下,上面介绍的成员访问运算符与强制类型转换运算符的实现方式并没有发生本质的变化。而与其他运算符类似的是,编译器会减少对栈内存的使用。同时,基于更强的静态分析能力,编译器甚至可以提前推算出某些变量的取值,并省去在程序运行过程中再进行类型转换的过程,从而进一步提升程序的运行时性能。
总结
- 通常来说,算数、关系、位、赋值运算符的实现在大多数情况下,都会直接一一对应到特定的汇编指令上;
- 逻辑运算符的实现方式则有些不同,它会首先借助 test 、 cmp 等指令,来判断操作数的状态,并在此基础上再进行相应的数值转换过程;
- 在成员访问运算符中,取地址运算符一般对应于汇编指令 lea ,解引用运算符则可直接使用 mov 指令来实现;
- 对于其他运算符,sizeof 运算符会在编译时进行求值,强制类型转换运算符则直接对应于不同指令对同一块数据的不同处理方式。



