C 语言中的量值与数据
量值可以被粗略地分为变量(variable)与常量(constant),其中变量是指值可以在整个应用程序的生命周期中被多次改变的量;而常量则与之相反,在被定义后便无法被再次修改。
变量
C 语言为我们提供了众多的语言关键字(keyword)以用来定义相应类型的数据。比如在下面这个例子中,我们通过以下几步成功定义了多个变量:
- 使用 int 等关键字,来指定数据的具体类型;
- 为该数据设置一个名称;
- 通过 “=” 赋值运算符为该数据设定具体的值。
int x = -10; // 定义一个整型变量;
char y = 'c'; // 定义一个字符变量;
double z = 2.0; // 定义一个双精度浮点变量;C 语言中变量类型占用的具体字节大小,还与程序运行所在的硬件体系结构紧密相关,这也是 C 语言与其他高级编程语言有所不同的地方。
C 语言最初被设计时,高效性就是设计者考虑的一个主要因素。因此 C 标准委员会在考虑语言设计时,会参考来自于底层硬件体系的某些因素。比如,C 标准中规定,int 类型的大小为执行环境架构体系所建议的自然大小。所谓自然大小,可以简单理解为:对于该大小的数据,硬件体系能够以最高的效率进行处理。因此,硬件体系不同,对应的自然大小便也不同,这也就意味着同一种 C 变量类型在不同硬件体系上可能会有着不同的大小。
除了可以为变量指定不同的数据类型外,同大多数其他静态类型语言类似,在 C 语言中,整型变量本身还需区分它们的“符号性(signedness)”。简单来说,其实就是两种情况:若类型仅可以存放正数,则为无符号(unsigned)类型;若正负数都可以存储,则为有符号(signed)类型。符号性上的区别有利于程序对某些特定的场景需求进行优化。
常量
在 C 语言中,通过内联方式直接写到源代码中的字面量值一般被称为“常量”。
用 const 关键字按照与定义变量相同语法定义的量,不也是常量吗?它与字面量常量有什么区别呢?
通常来说,在 C 语言中,使用 const 关键字修饰的变量定义语句,表示对于这些变量,我们无法在后续的程序中修改其对应或指针指向的值。因此,我们更倾向于称它们为“只读变量”,而非常量。当然,在程序的外在表现上,二者有一点是相同的:其值在第一次出现时便被确定,且无法在后续程序中被修改。
只读变量与字面量常量的一个最重要的不同点是,使用 const 修饰的只读变量不具有“常量表达式”的属性,因此无法用来表示定长数组大小,或使用在 case 语句中。常量表达式本身会在程序编译时被求值,而只读变量的值只能够在程序实际运行时才被得知。并且,编译器通常不会对只读变量进行内联处理,因此其求值不符合常量表达式的特征。
#include <stdio.h>
int main(void) {
const int vx = 10;
const int vy = 10;
int arr[vx] = {1, 2, 3}; // [错误1] 使用非常量表达式定义定长数组;
switch(vy) {
case vx: { // [错误2] 非常量表达式应用于 case 语句;
printf("Value matched!");
break;
}
}
}数据的存储形式
计算机在看待数据时,并不会区分其符号性,而符号性的差异仅体现在计算机指令操作数据时的具体使用方式上。
计算机不会区分数据的符号性,符号性的差异仅由计算机指令如何使用数据而定。比如在 C 语言中,当对某类型变量进行强制类型转换时,其底层存储的数据并不会发生实质的变化,而仅是程序对如何解读这部分数据的方式发生了改变。比如下面这个例子:
#include <stdio.h>
int main(void) {
signed char x = -10;
unsigned char y = (unsigned char)x;
printf("%d\n", y); // output: 246.
return 0;
}其中,有符号整型变量 x 会按照位模式 1111 0110 的补码形式存放有符号数 -10,而如果将该序列按照无符号整数的位模式进行解读,则可得到如程序运行输出一样的结果,即无符号整数值 246。 总之,程序在进行强制类型转换时,不会影响其底层数据的实际存储方式。
在 C 语言中,关于数据使用还有一个值得注意的问题:变量类型的隐式转换(Implicit Type Conversion)。C 语言作为一种弱类型语言,其一大特征就是在某些特殊情况下,变量的实际类型会发生隐式转换。
#include <stdio.h>
int main(void) {
int x = -10;
unsigned int y = 1;
if (x < y) {
printf("x is smaller than y.");
} else {
printf("x is bigger than y."); // this branch is picked!
}
return 0;
}实际上,在上面的代码中,程序逻辑在真正进入到条件语句之前,变量 x 的类型会首先被隐式转换为 unsigned int ,即无符号整型。而根据数据类型的解释规则,原先存放有 -10 补码的位模式会被解释为一个十分庞大的正整数,而这个数则远远大于 1。
同整数一样,C 语言在对浮点数进行类型转换时(无论隐式还是显式),也都不会对底层存放的浮点数据进行改动,而只是将对应位序列的解释方式从浮点数改为了其他方式。在 C 语言中,双精度浮点类型 double 具有作为隐式类型转换的最高优先级。当在一个表达式中存在该类型的变量时,计算机会首先将其他参与变量均转换为该类型,然后再进行表达式求值。
数据的存储位置
在 C 语言中,通过不同的语法形式,我们可以定义具有不同数据类型的变量,这些变量按照其定义所在位置,可以被划分为局部变量、全局变量。进一步地,通过添加 static 关键字,可以将变量标记为静态类型,以延长变量的生存期,并限定其可见范围为当前编译单元,即当前所在源文件;通过添加 register 关键字,还可以建议编译器将变量值存放到寄存器中,以提升其读写性能。
对于上面提到的这些变量形式,其可能的数据存放位置均不尽相同。根据变量定义时使用的不同语法形式,我总结了变量数据的可能存放位置,如下表所示:
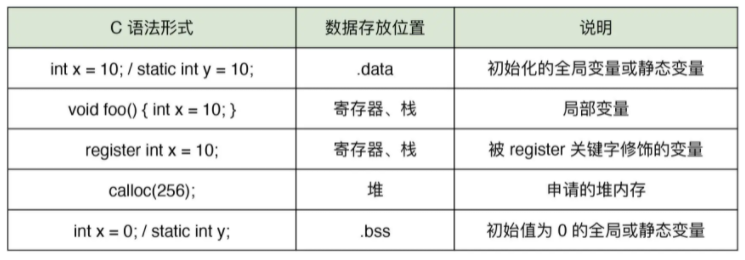
需要注意的是,表格里和这一讲后面提到的以 “.” 作为开头的标识,都指代对应的 Section 结构。
- 初始化的全局变量和静态变量:这类变量的值具有与应用程序同样长的生命周期,其值通常会被存放到进程 VAS(Virtual Address Space,虚拟地址空间)内的 .data 中。应用程序在被正常加载和运行前,需要首先将应用程序代码,及其相关依赖项的数据映射到内存中的某个位置,这段包含有应用程序正常运行所必备数据的内存段即进程的 VAS。像 .data 等以 “.” 开头作为标记的 Section 结构,都代表着该内存段中的某个具体位置,这些 Section 结构都为应用的正常运行提供了各方面支持。
- 局部变量:一般来说,这些变量将被存放在寄存器或应用程序 VAS 的栈内存中,具体使用哪种方式则依赖于编译器的选择。
- 其他:未初始化的全局变量和静态变量,以及直接通过 malloc、calloc 等标准库函数创建的内存块中所包含的数据,其存放位置也有所不同。它们被分别存放到进程 VAS 的 .bss 以及堆内存中。不同类型常量数据的存储方式也会有所不同。如下表所示,由于常量本身的不可变特征,它们会按照数据的大小和类型被选择性存放到进程 VAS 的 .rodata 以及 .text 中。其中,.rodata 用于存放只读(Read-only Data)数据,而 .text 通常用于存放程序本身的代码。

一般的规律是,若内联的常量值较大,则会被单独存放到 .rodata 中保存,否则会直接内联到应用程序代码中,作为机器指令(比如最常见的 mov 指令)的字面量参数。



